


【期刊信息】
Message刊名:计算机光盘软件与应用
主办:中国大恒公司大恒电子出版社
主管:中国科学院
ISSN:1007-9599
CN:11-3907/TP
语言:中文
周期:半月
影响因子:0
期刊分类:计算机软件及计算机应用

Oceanus的实时流式计算实践与优化
作者:网站采编
关键词:
导语?|?随着互联网场景的不断深化发展,业务实时化趋势越来越强,要求也越来越高。特别是在广告推荐、实时大屏监控、实时风控、实时数仓等各业务领域,实时计算已经成为了不可或缺的一环。在大数据技术的不断发展的过程中,Flink已经成为实时计算的工业标准,越来越多的公司正在使用 Flink作为自己实时计算的工具。本文由腾讯云实时计算Oceanus专家工程师杜立在 Techo TVP开发者峰会「数据的冰与火之歌——从在线数据库技术,到海量数据分析技术」 的《实时流式计算实践与优化》演讲分享整理而成,为大家详尽介绍在使用Flink SQL开发计算作业过程中,针对遇到的痛点,腾讯云实时计算服务Oceanus所进行的优化与扩展,以及实践总结。
点击可观看精彩演讲视频
一、腾讯云流计算服务
今天的内容主要分两大部分:第一部分向大家快速介绍现在腾讯云上流式计算服务的基本情况,后一个较大的重点分为三个部分——我们在实时的业务过程中针对Flink SQL所遇到的技术上的痛点、在改造这些痛点的过程中所遇到的技术挑战,以及在整个实践过程中所做的技术方案和内容。
这是现在腾讯云实时计算服务的运营情况,目前在客户方面我们既有内部客户,也有外部客户。在外部客户方面,像B站、叮咚买菜等互联网公司都使用了我们的实时计算服务。内部业务像比较重要的微信、QQ、QQ音乐、腾讯视频等都已经使用了我们的实时计算服务。目前整个实时计算的计算规模已经超过了3万核,每天的数据接入量超过5PB,日实时计算量超过50万/次,而且这个规模还在不断地增长。
 我们整个服务的研发方向也分为四块:首先是想降低用户在使用我们的计算服务以及开发他自己的Flink实时计算任务时的接入和学习成本,所以我们提供了一站式的开发平台。同时用户开发完自己的Flink job之后,可以直接在这个平台上进行线上测试,保证实时部署前的数据正确性。其次我们提供了一站式的部署功能,能够让实时的计算任务直接部署到腾讯云的TKE容器上。最后是运维工具,任务部署到TKE之后,需要实时掌握实际运营情况,包括它的失败告警以及实际的运营指标等,我们提供了一系列的运维工具,帮助用户快速解决线上的问题。
我们整个服务的研发方向也分为四块:首先是想降低用户在使用我们的计算服务以及开发他自己的Flink实时计算任务时的接入和学习成本,所以我们提供了一站式的开发平台。同时用户开发完自己的Flink job之后,可以直接在这个平台上进行线上测试,保证实时部署前的数据正确性。其次我们提供了一站式的部署功能,能够让实时的计算任务直接部署到腾讯云的TKE容器上。最后是运维工具,任务部署到TKE之后,需要实时掌握实际运营情况,包括它的失败告警以及实际的运营指标等,我们提供了一系列的运维工具,帮助用户快速解决线上的问题。
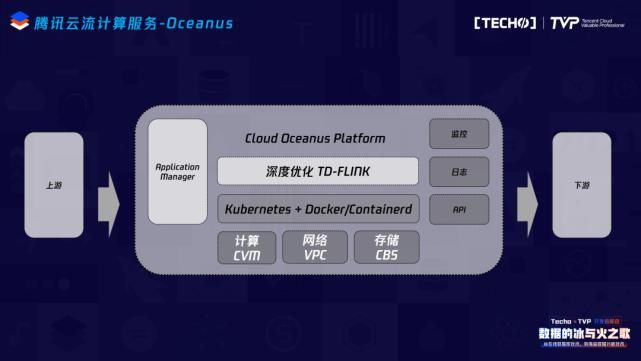 整个云上生态中,实时计算更多担当的是一个通道的角色,我们在上下游的生态和数据打通上花费了非常多的精力,包括修复了社区connector相关的一些bug、基本能支持大数据生态和腾讯云上所有基本组件的数据打通,目前我们也已经在内部测试的CDC Source、ClickHouse 等connector,最近应该会上线跟大家见面。
整个云上生态中,实时计算更多担当的是一个通道的角色,我们在上下游的生态和数据打通上花费了非常多的精力,包括修复了社区connector相关的一些bug、基本能支持大数据生态和腾讯云上所有基本组件的数据打通,目前我们也已经在内部测试的CDC Source、ClickHouse 等connector,最近应该会上线跟大家见面。
接下来的内容是今天的重点——我们在Flink SQL上所做的工作,在展开之前,我带大家快速回顾Flink SQL的基本概念和情况。
二、Flink SQL概况
首先看Flink的编程模型,Flink本身提供了三层编程模型供大家使用,最底层的是Data Stream和Data Set API,是一个java API,往上Table这一层是它基于类似于DSL的领域建模语言,再往上是它的Flink SQL,越往上它的抽象层次会越高,也就意味着用户在使用不同的编程接口的时候,越往上所需要花费的学习成本和接入成本会更低。所以在实际接入过程中还是希望用户能够使用我们的Flink SQL,因为本身SQL的特点也是非常明显的,首先它是标准化的语言,不同背景的人员来使用SQL都能够快速阅读当前这一段SQL所表达的业务逻辑,同时它底层跟计算引擎和版本可能都是解耦的,所以后续的版本升级、平台迁移都是比较轻量级的。但是它也有它的不足之处,越往上抽象,它可能会流失一些基本的功能,即Flink SQL并没有涵盖到所有的DataStream或者说Flink原语的语义,所以我们也希望大家和社区一起共建这部分的能力。
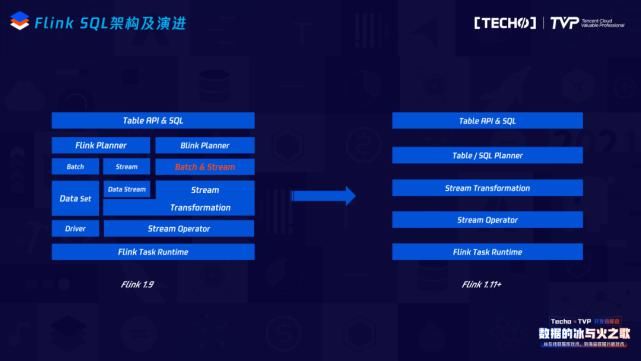
 再看当前Flink SQL的架构及演进,这其实是Flink1.9和Flink1.9之后的变化,最主要的变化是在Flink1.9之前它经过了Data Set或者Data Stream的一层转换,也就是说转成最终的Stream Graph时,它会调用Data Stream或者Data Set的API;但是在Flink1.9之后,它其实把这一层拿掉了,即在SQL Node变成Stream Graph时,用Stream Transformation就可以达到直接转化Stream Graph。它的优点显而易见,抽掉了中间这一层,可以保证在做SQL优化代码和逻辑正确化优化的规则上都可以共享,不再区分它的流与批。
再看当前Flink SQL的架构及演进,这其实是Flink1.9和Flink1.9之后的变化,最主要的变化是在Flink1.9之前它经过了Data Set或者Data Stream的一层转换,也就是说转成最终的Stream Graph时,它会调用Data Stream或者Data Set的API;但是在Flink1.9之后,它其实把这一层拿掉了,即在SQL Node变成Stream Graph时,用Stream Transformation就可以达到直接转化Stream Graph。它的优点显而易见,抽掉了中间这一层,可以保证在做SQL优化代码和逻辑正确化优化的规则上都可以共享,不再区分它的流与批。
 这是一条SQL从SQL文本转成最终Flink Job的过程,主要分五步:第一步调Flink依赖里的JavaCC,将这个文本转成AST语法树,也就是它的SQL Node,SQL Node后会调一个Validate接口,这里Validate的内容就是SQL的一些元数据,经过这两步之后就完成了一条SQL的语法分析和语义分析。再往后SQL Node会转成Rel Node,最终会转成Flink的Native Code,中间会做一些优化,包括:逻辑执行计划优化和物理执行计划优化。最终的执行计划变成Native Code,中间我们有两种方式去生成最终的Flink代码,一种是通过一些规则的方式静态地编码,另外一种是如果逻辑比较灵活的话,可能需要通过动态代码生成技术,将代码生成架构文件之后在内存里进行编译,直接部署到Flink集群上。
这是一条SQL从SQL文本转成最终Flink Job的过程,主要分五步:第一步调Flink依赖里的JavaCC,将这个文本转成AST语法树,也就是它的SQL Node,SQL Node后会调一个Validate接口,这里Validate的内容就是SQL的一些元数据,经过这两步之后就完成了一条SQL的语法分析和语义分析。再往后SQL Node会转成Rel Node,最终会转成Flink的Native Code,中间会做一些优化,包括:逻辑执行计划优化和物理执行计划优化。最终的执行计划变成Native Code,中间我们有两种方式去生成最终的Flink代码,一种是通过一些规则的方式静态地编码,另外一种是如果逻辑比较灵活的话,可能需要通过动态代码生成技术,将代码生成架构文件之后在内存里进行编译,直接部署到Flink集群上。
文章来源:《计算机光盘软件与应用》 网址: http://www.jsjgprjyyy.cn/zonghexinwen/2021/0522/1234.html
投稿电话: 投稿邮箱: